Spring BootでOracleデータベースに接続する方法
Spring BootでOracleデータベースに接続する方法です。

Spring Bootでは、JPA(Java Persistence API)というライブラリを利用してデータベースへアクセスします。JPA は SQL を書かずに CRUD(クラッド) ができるのと、データベースのレコードと Java オブジェクトをマッピングし、オブジェクトとしてデータを扱えるようになる、いわゆる O/R マッピングできることが特徴です。
CRUD: Create(生成)、Read(読み取り)、Update(更新)、Delete(削除)のこと
今回は Oracleを使いますが、データベースは何でもよいです。mySQL や PostgreSQL など、慣れているものや既に環境が用意されているものを使いましょう。
ここでは Spring BootでOracleデータベースに接続する方法 を紹介します。
目次
環境
- Spring Boot 1.4.1
- Thymeleaf 3.0.2
- Windows7
- Java8
- Eclipse 4.6 Neon
- Oracle 11g
こちらのページを参考にサンプルアプリを作ってください。既にSpring Bootアプリがある場合は、読み飛ばして結構です。
pom.xmlを編集
まず pom.xml に jpa のリポジトリ設定を追加します。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
次に jdbc のリポジトリ設定を追加したいところですが・・・、Oracleのリポジトリ設定は面倒なので、サイトからダウンロードしてローカルに配置します。
・Oracle Database 12c Release 1 JDBC Driver Downloads
ダウンロードするファイルは ojdbc7.jar です。JDK7 & JDK8 で Oracle 12.1.0.x、11.2.0.x、11.1.0.x に接続できます。
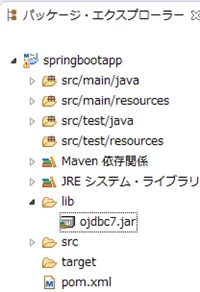
pom.xml に下記を追記します。
<dependency>
<groupId>com.oracle</groupId>
<artifactId>ojdbc7</artifactId>
<version>12.1.0</version>
<scope>system</scope>
<systemPath>${basedir}/lib/ojdbc7.jar</systemPath>
</dependency>
version は、接続できる Oracle のバージョンに合わせているだけですので、なんでもいいですよ。
詳しくは、こちらの「Mavenプロジェクトにローカルjarファイルを追加する方法」「MavenリポジトリにないローカルjarをPom.xmlに書く方法」を参考にしてください。
application.ymlを編集
"src/main/resources/config"に、application.properties か application.yml を配置します。どちらでもいいですが、yaml の方が好みなので、application.yml で進めます。
spring:
datasource:
url: jdbc:oracle:thin:@localhost:1521:oracle
username: scott
password: tiger
driverClassName: oracle.jdbc.driver.OracleDriver
jdbc:oracle:thin:@(ホスト名):(ポート番号):(接続するデータベースのSID)
テーブルを作る
サンプルとして従業員テーブルを作ります。
CREATE TABLE EMPLOYEES
(
ID NVARCHAR2(255) NOT NULL,
NAME NVARCHAR2(255) NOT NULL,
EMAIL NVARCHAR2(255),
CONSTRAINT PK_EMPLOYEES PRIMARY KEY (ID) USING INDEX
);
データは適当で。ここでは2件登録しました。
INSERT INTO EMPLOYEES VALUES('1','サカエン','saka-en@example.com');
INSERT INTO EMPLOYEES VALUES('2','エンサカ','en-saka@example.com');
Spring Bootはクラスパス直下に、下記のファイルがあると自動で実行してくれます。
- schema-(platform).sql
- schema.sql
- data-(platform).sql
- data.sql
schema にはテーブル定義用のDDLを、data には初期データ用の DML を記載することになりますが、どのファイルも起動するたびに実行されてしまう点に注意が必要です。つまり、テーブルが存在する場合はエラーになるし、同一キーのデータが存在すればエラーになります。実務では使わないと思いますので、ここでは紹介程度で。
Entityクラスを作る
テーブルのカラムと同名のフィールドを宣言する Entity クラスを作ります。
package springbootapp;
import javax.persistence.Entity;
import javax.persistence.Id;
import lombok.Data;
@Data
@Entity
public class Employees {
@Id
private String id;
private String name;
}
テーブル名とエンティティの名前が違う場合は、@Table アノテーションを付加します。
例として労働日数を管理する "WORKING_DAYS" というテーブルがあった場合、
@Table(name="working_days")
public class WorkingDays {
となります。
Repositoryインタフェースを作る
このリポジトリで JPA を継承すれば、SQL を書かずに済みます。
package springbootapp;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.data.jpa.repository.JpaRepository;
public interface EmployeesRepository extends JpaRepository<Employees, String> {
Page<Employees> findAll(Pageable pageable);
}
継承する JpaRepository は、
< 扱うエンティティ・クラス , プライマリキーの型 >
という、2種類のタイプを指定することで、そのエンティティに特化したリポジトリとして扱われるようになります。
Controllerを作る
Controllerに下記を追記します。
@Autowired
EmployeesRepository employeesRepository;
System.out.println("[START] ORALCEに接続して従業員データを取得します。");
Page<Employees> emps = employeesRepository.findAll(new PageRequest(0, 10));
for (Employees emp : emps) {
System.out.println(emp.getId() + " : " + emp.getName() + " : " + emp.getEmail());
}
System.out.println("[END ] ORALCEに接続して従業員データを取得します。");
全体としてはこんな感じです。
package springbootapp;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RequestParam;
@Controller
public class HelloWorldController {
@Autowired
EmployeesRepository employeesRepository;
@RequestMapping(name = "/", method = RequestMethod.GET)
public String helloWorld(Model model) {
model.addAttribute("message", "こんにちは世界");
System.out.println("[START] ORALCEに接続して従業員データを取得します。");
Page<Employees> emps = employeesRepository.findAll(new PageRequest(0, 10));
for (Employees emp : emps) {
System.out.println(emp.getId() + " : " + emp.getName() + " : " + emp.getEmail());
}
System.out.println("[END ] ORALCEに接続して従業員データを取得します。");
return "index";
}
@RequestMapping(name = "/", method = RequestMethod.POST)
public String nameToMessage(@RequestParam("name") String name, Model model) {
model.addAttribute("message", "こんにちは" + name + "さん");
return "index";
}
}
アプリを起動してブラウザから localhost:8080 にアクセスすれば・・・
[START] ORALCEに接続して従業員データを取得します。
2016-11-22 17:02:39.622 INFO 10140 --- [nio-8080-exec-1] o.h.h.i.QueryTranslatorFactoryInitiator : HHH000397: Using ASTQueryTranslatorFactory
1 : サカエン : saka-en@example.com
2 : エンサカ : en-saka@example.com
[END ] ORALCEに接続して従業員データを取得します。
おおお、データ取得できましたー^^
条件指定クエリーを実装してみる
上の実装では全件データ取得でしたが、条件指定したクエリーも実装します。実装には JPQL(Java Persistence Query Language) を使います。JPQL は JPA で標準化されている SQL に似た構文を持つ問い合わせ言語です。データベースに依存しないクエリを発行することができるのが特徴です。
今回は、名前を"サカエン"って指定してレコードを抽出してみましょう。仮に同じ名前の人がいた場合も考慮して、1件目だけ抽出するように変更します。同時に、"サカ"って名前が含まれるレコードを抽出して、IDの降順に並び替えます。こちらはネイティブな SQL を実行してみます。
Repository クラスに下記を追記します。
List<Employees> findByName(@Param("name") String name);
@Query(value="select * from employees where name like %:name% order by id desc", nativeQuery=true)
List<Employees> findByNameOrderByIdDesc(@Param("name") String name);
SELECT <取得するインスタンスやプロパティ> FROM <エンティティ名> [AS] <別名>
JPQL の構文は、基本的には SQL と同じ形式になっているものの、FROM 句はテーブルではなく、エンティティを指しています。必ずエンティティの別名を定義しなければなりません。大文字小文字の区別は、予約語やエンティティの別名は区別されないものの、エンティティ名やプロパティ名は区別されるので注意が必要です。
また、"*"(アスタリスク) は存在しないので "select * from ..." は記述できません。"*"(アスタリスク) は速度低下を招きますので、できるだけ使わないようにしましょう。(ここでは使っているけど^^;)
上記の findByName を例を挙げると、
SELECT e FROM Employees e where e.name=:name
のようになります。
これを回避する方法として nativeQuery=true を付加すると、ネイティブな SQL を実行できます。
EmployeesService という interface クラスを作ります。
package springbootapp;
import java.util.List;
public interface EmployeesService {
public Employees findByName(String name);
public List<Employees> findByNameOrderByIdDesc(String name);
}
EmployeesService クラスを implements したクラスを作成します。
package springbootapp;
import java.util.List;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class EmployeesServiceImpl implements EmployeesService {
@Autowired
EmployeesRepository employeesRepository;
@Override
public Employees findByName(String name) {
List<Employees> employees = employeesRepository.findByName(name);
Employees employee = new Employees();
if ( employees.size() > 0 )
employee = employees.get(0);
return employee;
}
@Override
public List<Employees> findByNameOrderByIdDesc(String name) {
return employeesRepository.findByNameOrderByIdDesc(name);
}
}
コントローラーに下記を追記します。
@Autowired
EmployeesService employeesService;
Employees employee = employeesService.findByName("サカエン");
System.out.println("名前='サカエン'のメールアドレス:");
System.out.println(" " + employee.getEmail());
List<Employees> employees = employeesService.findByNameOrderByIdDesc("サカ");
System.out.println("名前 Like '%サカ%'のID降順:");
for (Employees emp : employees) {
System.out.println(" " + emp.getId() + " : " + emp.getName() + " : " + emp.getEmail());
}
早速、実行してみましょう。
名前='サカエン'のメールアドレス:
saka-en@example.com
名前 Like '%サカ%'のID降順:
2 : エンサカ : en-saka@example.com
1 : サカエン : saka-en@example.com
おおお、予定通りの結果が得られましたー^^
プロパティファイルに名前付きクエリーを定義してみる
"src/main/resources/META-INF/" 配下に "jpa-named-queries.properties" を作れば、JPQLをプロパティファイルで管理することができます。
#Employees
employees.findByEmailLike=select e from Employees e where e.email like %:email% order by id
Repository クラスに下記を追記します。
@Query(name="employees.findByEmailLike")
List<Employees> findByEmailLike(@Param("email") String email);
Service クラスに下記を追記します。
public List<Employees> findByEmailLike(String email);
ServiceImpl クラスに下記を追記します。
@Override
public List<Employees> findByEmailLike(String email) {
return employeesRepository.findByEmailLike(email);
}
コントローラーに下記を追記します。
List<Employees> empEmails = employeesService.findByEmailLike("saka");
System.out.println("email Like '%saka%'のID順:");
for (Employees emp : empEmails) {
System.out.println(" " + emp.getId() + " : " + emp.getName() + " : " + emp.getEmail());
}
実行するとこんな感じで。
email Like '%saka%'のID順:
1 : サカエン : saka-en@example.com
2 : エンサカ : en-saka@example.com
ふむふむ、うまくできました^^
まとめ
Spring BootでOracleデータベースに接続する方法を紹介しました。
今回は初めて Spring Boot でデータベースアクセスしてみましたが、JPA がいい感じなことがわかりました^^
でも、個人的には S2JDBC で好んで開発していたので、2 Way SQL でないことに少し違和感があるんですよねー。
結局、実務だと複雑な SQL をゴリゴリ書かなければならないケースが出てくるので、2 Way SQL できないかなーと悩んでいます。調べたところ Doma2 ってのが有効っぽいので、次回はこの辺りを検証したいと思います。
おつかれさまでした。